
Вы читаете эту статью потому, что, как и я, с горячим интересом наблюдаете за возрастающей популярностью криптовалюты. И вам хочется понять, как работает блокчейн — технология, которая лежит в ее основе.
Но разобраться в блокчейне не так-то просто, по крайней мере, по моему опыту. Я корпел над заумными видео, продирался через туториалы и с нарастающей досадой отмечал недостаток иллюстрирующих примеров.
Я предпочитаю учиться в процессе работы. При таком раскладе мне приходится отрабатывать тему сразу на уровне кода, что помогает закрепить навык. Если вы последуете моему примеру, то к концу статьи у вас будет функционирующий блокчейн и ясное понимание, как это все работает.

Напомню: блокчейн — это неизменяемая, последовательная цепочка записей, которые называются блоками. Они могут заключать в себе транзакции, файлы и, в принципе, любые другие виды данных. Главное здесь — что они связаны друг с другом посредством хэшей.
Если вы не совсем понимаете, что такое хэш, вам сюда.
На кого рассчитано это руководство? На тех, кто без проблем может читать и писать несложный код на Python и в общих чертах представляет, как работают HTTP запросы — мы будет общаться с нашим блокчейном через HTTP.
Что будет нужно для работы? Проверьте, чтобы у вас был установлен Python 3.6+ (вместе с pip). Также вам нужно будет установить Flask и прекрасную библиотеку Requests:
Ах да, еще вам понадобится HTTP клиент, например, Postman или cURL. Тут подойдет любой.
Где можно посмотреть то, что получится в итоге? Исходный код доступен здесь.
Откройте свой любимый текстовый или графический редактор, мне вот, например, нравится PyCharm. Создайте новый файл под названием blockchain.py. Мы будем работать только в этом файле, а если запутаетесь, всегда можно подсмотреть в исходный код.
Представление блокчейна
Сначала мы создаем новый класс, конструктор которого создаст исходный пустой список (где и будет храниться наш блокчейн) и еще один — для транзакций. Вот как выглядит структура класса:
Класс Blockchain отвечает за управление цепочкой. Здесь будут храниться транзакции, а также некоторые вспомогательные методы для добавления в цепочку новых блоков. Давайте распишем эти методы.
Как выглядит блок?
В каждом блоке содержится индекс, метка времени (в Unix), список транзакций, доказательство и хэш предыдущего блока.
Вот пример того, как может выглядет отдельный блок:
Теперь идея цепочки должна быть очевидна — каждый блок включает в себя хэш предшествующего. Это очень важно: именно так обеспечивается неизменность цепочки: если хакер повредит какой-либо блок, то абсолютно все последующие будут содержать неверные хэши.
Понятно? Если нет, остановитесь и дайте себе время усвоить эту информацию — именно в ней состоит базовый принцип блокчейна.
Добавляем транзакции в блок
Нам нужно каким-то образом добавлять в блок новые транзакции. За это отвечает методnew_transaction(), работает он достаточно просто:
Когда new_transaction() добавляет новую транзакцию в список, он возвращает индекс блока, куда она была записана, следующему, с которым будет осуществляться майнинг. Позже это пригодится следующему пользователю, добавляющему транзакцию.
Помимо создания блока genesis в конструкторе, мы также распишем методы new_block(),new_transaction() и hash():
Вышеприведенный код, вероятно, в пояснениях не нуждается — я добавил кое-где комментарии и докстринги, чтобы было понятнее. С представлением блокчейна мы практически закончили. Но сейчас вы, должно быть, задаетесь вопросом, как происходит процесс создания, встраивания и майнинга блоков.
Разбираемся с доказательством работы
Алгоритм доказательства работы служит для создания новых блоков в блокчейне (это процесс еще называется майнингом). Цель доказательства работы — вычислить нужное значение, чтобы решить уравнение. Это значение должно быть сложно рассчитать (с математической точки зрения), но легко проверить любому участнику системы. В этом заключается основная идея доказательства работы.
Чтобы стало яснее, давайте рассмотрим очень простой пример.
Допустим, хэш некоторого числа X, помноженного на другое Y, должен оканчиваться на 0. Соответственно, hash(x * y) = ac23dc...0. Для этого упрощенного примера установим x = 5. Прописываем все это на Python:
Правильный ответ здесь: y = 21; именно при таком значении получается хэш с 0 в конце:
В биткойне алгоритм доказательства работы называется HashCash и не особенно отличается от простенького примера, приведенного выше. Это уравнение, которые майнеры наперегонки пытаются разрешить, чтобы создать новый блок. В целом, сложность определяется тем, сколько символов нужно вычислить в заданной последовательности. За верный ответ майнеры получают вознаграждение в виде одной монеты — в ходе транзакции.
Проверить их решение для системы не составляет труда.
Пишем простое доказательство работы
Теперь давайте пропишем подобный же алгоритм для нашего блокчейна. Условия возьмем в духе вышеприведенного примера:
Найдите число p, которое, будучи хэшировано с доказательством предыдущего блока, дает хэш с четырьмя нулями в начале.
Мы можем варьировать сложность этой задачи, меняя количество нулей в начале. Но четырех вполне достаточно. Вы можете сами убедиться, что один-единственный дополнительный нолик значительно замедляет процесс поиска решения.
Работа над классом почти завершена и теперь мы готовы начать взаимодействие с ним при помощи HTTP запросов.
Здесь мы будем использовать Python Flask — микрофреймворк, который облегчает процесс соотнесения конечных пунктов с функциями Python, что позволяет нам осуществлять диалог с блокчейном по Сети при помощи HTTP запросов.
Создаем три метода:
Настраиваем Flask
Наш «сервер» сгенерирует один-единственный узел сети в блокчейн-системе. Давайте напишем немного шаблонного кода:
Краткие пояснения к тому, что мы добавили:
Строка 15: Инстанцирует узел. Подробнее о Flask можно почитать здесь.
Строка 18: Создает произвольное имя для узла.
Строка 21: Инстанцирует класс Blockchain.
Строки 24-26: Создает конечную точку /mine, то есть запрос GET.
Строки 28-30: Создает конечную точку /transactions/new, то есть запрос POST, так как именно туда мы и будем отсылать данные.
Строки 32-38: Создает конечную точку /chain, который возвращает блокчейн целиком.
Строки 40-41: Запускает сервер на порту 5000.
Конечный пункт для транзакций
Вот как будет выглядеть запрос на транзакцию. Именно это пользователь отсылает на сервер:
Метод класса для добавления транзакции в блок у нас уже есть, поэтому дальше все легко. Давайте напишем функцию для добавления транзакции:
Конечный пункт для майнинга
Именно в этой конечной точке творится вся магия, но ничего особо сложного в нем нет. Она должна делать три вещи:
Обратите внимание, что в качестве получателя созданного блока указан адрес узла. Большая часть того, что мы тут делаем, сводится к взаимодействию с методами нашего класса Blockchain. По завершению этого шага основная работа закончена, можно начинать диалог.
Для взаимодействия с API в рамках системы можно использовать старый-добрый cURL или Postman.
Запускаем сервер:
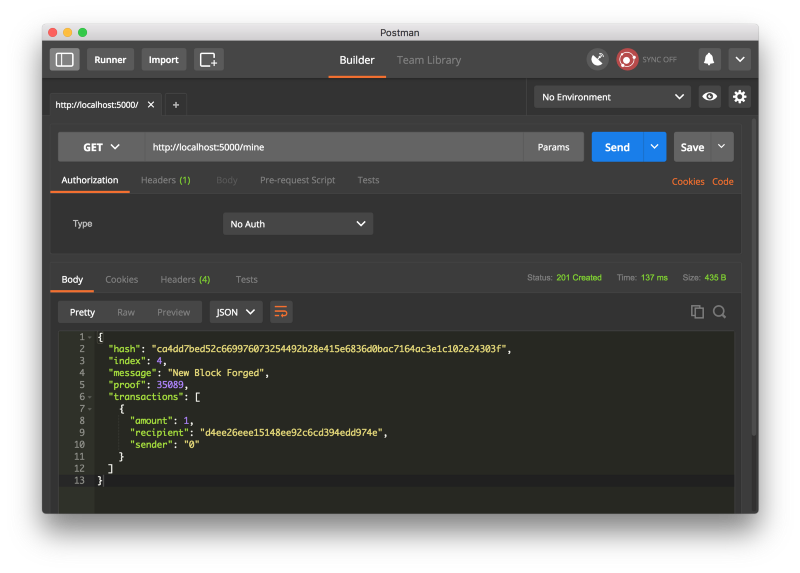
Давайте попробуем создать блок, отправив запрос GET по адресу localhost:5000/mine:
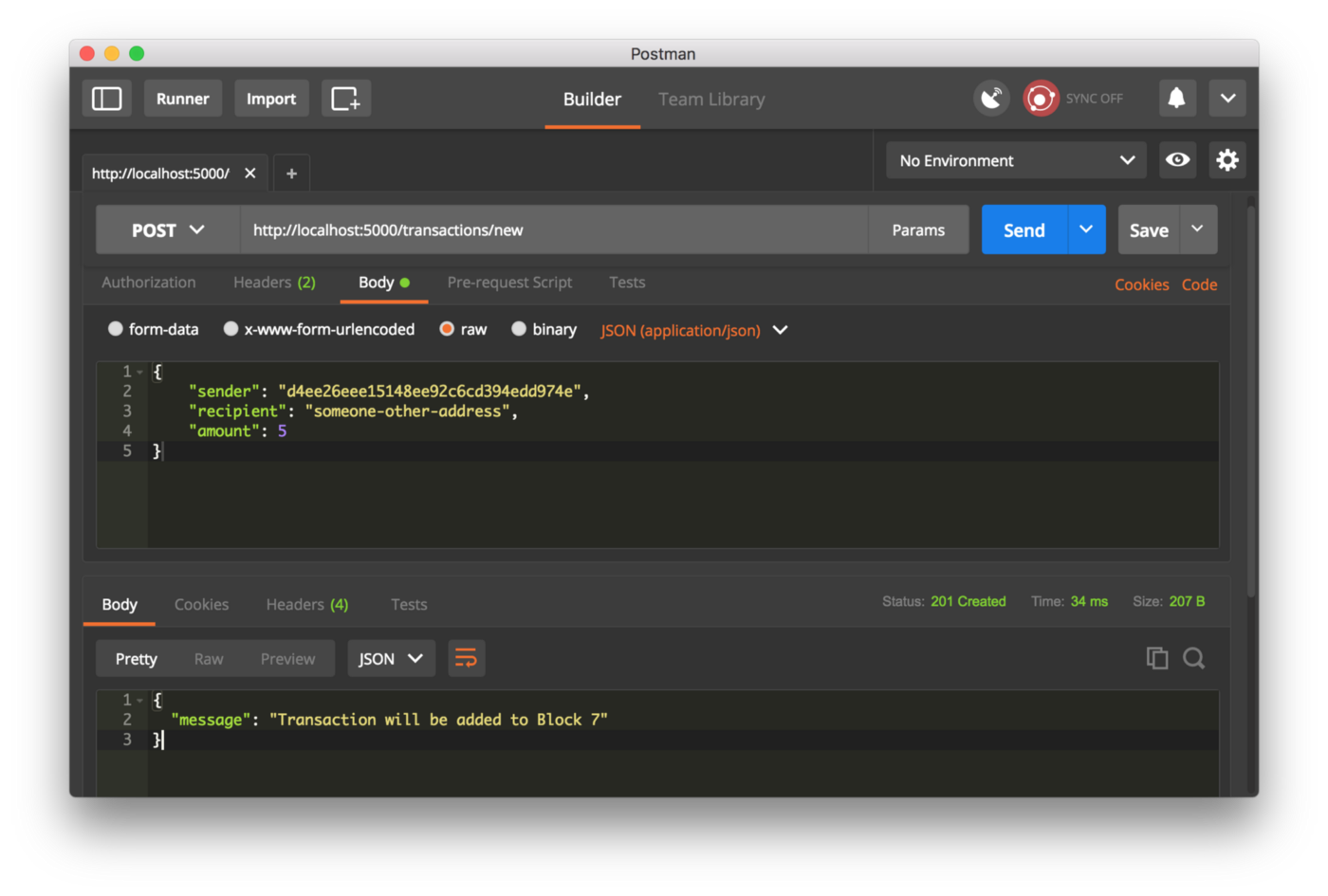
Теперь создаем новую транзакцию, отправив запрос POST, содержащий ее структуру, по адресуlocalhost:5000/transactions/new:
Если вы работаете не с Postman, вот как сформулировать аналогичный запрос в cURL:
Я перезапустил сервер и создал еще два блока, чтобы в итоге получилось три. Давайте изучим получившуюся цепочку через запрос localhost:5000/chain:
Все это очень здорово. У нас есть простой блокчейн, который позволяет осуществлять транзакции и создавать новые блоки. Но блокчейн имеет смысл только в том случае, если он децентрализован. А если сделать его децентрализованным, как мы вообще можем гарантировать, что везде будет отображаться одна и та же цепочка? Это называется проблемой консенсуса. Если мы хотим, чтобы в системе было больше одного узла, придется ввести алгоритм консенсуса.
Распознаем новые узлы
Прежде чем внедрять алгоритм консенсуса, нам нужно что-то предпринять, чтобы каждый узел в системе знал о существовании соседних. У каждого узла в системе должен быть реестр всех остальных узлов. А значит понадобятся дополнительные конечные точки:
Нам нужно подкорректировать конструктор блокчейна и обеспечить метод для регистрации узлов:
Заметьте: мы использовали set() для хранения списка узлов. Это нехитрый способ гарантировать, что при добавлении новых узлов будет соблюдаться индемпотентность — то есть сколько бы раз мы ни добавляли какой-то конкретный узел, он будет засчитан только единожды.
Внедряем алгоритм консенсуса
Как я уже упоминал, конфликт происходит тогда, когда цепочка одного узла отличается от цепочки другого. Чтобы его устранить, мы введем такое правило: прерогатива всегда у той цепочки, которая длиннее. Иными словами, самая длинная цепочка в системе рассматривается как фактическая. Используя такой алгоритм, мы достигаем консенсуса среди всех узлов системы:
Первый метод valid_chain() отвечает за проверку цепочек на валидность, проходя каждый блок и верифицируя и хэш, и доказательство.
resolve_conflicts() — метод, который прорабатывает все соседние узлы: скачивает их цепочки и проверяет их описанным выше способом. Если при этом найдена валидная цепочка длиннее, чем наша, производится замена.
Давайте введем в наш API две конечные точки, один для добавления соседних узлов, другой для разрешения конфликтов:
На данном этапе, если хотите, можете привлечь другие машины и насоздавать разных узлов для вашей системы. Или добиться того же используя разные порты на одной машине. Я создал новый узел на другом порте той же машины, и позволил исходному узлу его распознать. Таким образом, получилось два узла: localhost:5000 и localhost:5001.

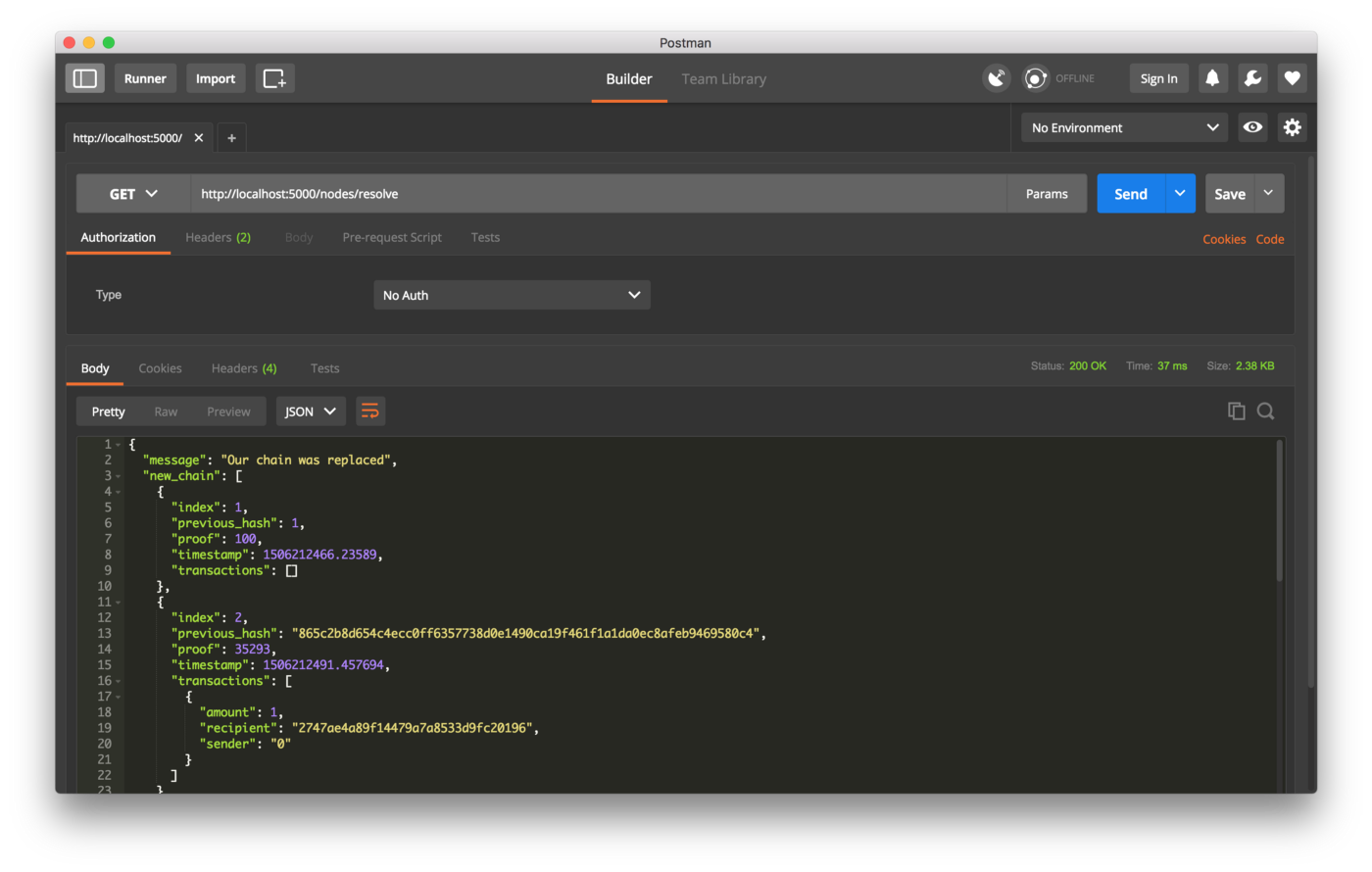
В узел номер два я добавил побольше блоков, чтобы цепочка получилась однозначно длиннее. После чего вызвал GET /nodes/resolve в первом узле — и алгоритм консенсуса заменил его цепочку на цепочку второго.
Ну, вот и все. Теперь собирайте друзей и тестируйте вам блокчейн совместными усилиями.
Надеюсь, этот материал вдохновит вас на новые идеи. Лично я с большим энтузиазмом наблюдаю за развитием криптовалюты: я уверен, что блокчейн перевернет наши представления об экономике, управлении государством и хранении информации.
В будущем я планирую выпустить вторую часть статьи, где мы добавим в блокчейн механизм валидации транзакций и поговорим о том, как все это можно использовать в продуктах.
Источник: https://habrahabr.ru/company/everydaytools/blog/339280/
Но разобраться в блокчейне не так-то просто, по крайней мере, по моему опыту. Я корпел над заумными видео, продирался через туториалы и с нарастающей досадой отмечал недостаток иллюстрирующих примеров.
Я предпочитаю учиться в процессе работы. При таком раскладе мне приходится отрабатывать тему сразу на уровне кода, что помогает закрепить навык. Если вы последуете моему примеру, то к концу статьи у вас будет функционирующий блокчейн и ясное понимание, как это все работает.
Но для начала…
Напомню: блокчейн — это неизменяемая, последовательная цепочка записей, которые называются блоками. Они могут заключать в себе транзакции, файлы и, в принципе, любые другие виды данных. Главное здесь — что они связаны друг с другом посредством хэшей.
Если вы не совсем понимаете, что такое хэш, вам сюда.
На кого рассчитано это руководство? На тех, кто без проблем может читать и писать несложный код на Python и в общих чертах представляет, как работают HTTP запросы — мы будет общаться с нашим блокчейном через HTTP.
Что будет нужно для работы? Проверьте, чтобы у вас был установлен Python 3.6+ (вместе с pip). Также вам нужно будет установить Flask и прекрасную библиотеку Requests:
Ах да, еще вам понадобится HTTP клиент, например, Postman или cURL. Тут подойдет любой.
Где можно посмотреть то, что получится в итоге? Исходный код доступен здесь.
Шаг первый: Делаем блокчейн
Откройте свой любимый текстовый или графический редактор, мне вот, например, нравится PyCharm. Создайте новый файл под названием blockchain.py. Мы будем работать только в этом файле, а если запутаетесь, всегда можно подсмотреть в исходный код.
Представление блокчейна
Сначала мы создаем новый класс, конструктор которого создаст исходный пустой список (где и будет храниться наш блокчейн) и еще один — для транзакций. Вот как выглядит структура класса:
Класс Blockchain отвечает за управление цепочкой. Здесь будут храниться транзакции, а также некоторые вспомогательные методы для добавления в цепочку новых блоков. Давайте распишем эти методы.
Как выглядит блок?
В каждом блоке содержится индекс, метка времени (в Unix), список транзакций, доказательство и хэш предыдущего блока.
Вот пример того, как может выглядет отдельный блок:
Теперь идея цепочки должна быть очевидна — каждый блок включает в себя хэш предшествующего. Это очень важно: именно так обеспечивается неизменность цепочки: если хакер повредит какой-либо блок, то абсолютно все последующие будут содержать неверные хэши.
Понятно? Если нет, остановитесь и дайте себе время усвоить эту информацию — именно в ней состоит базовый принцип блокчейна.
Добавляем транзакции в блок
Нам нужно каким-то образом добавлять в блок новые транзакции. За это отвечает методnew_transaction(), работает он достаточно просто:
Когда new_transaction() добавляет новую транзакцию в список, он возвращает индекс блока, куда она была записана, следующему, с которым будет осуществляться майнинг. Позже это пригодится следующему пользователю, добавляющему транзакцию.
Помимо создания блока genesis в конструкторе, мы также распишем методы new_block(),new_transaction() и hash():
Вышеприведенный код, вероятно, в пояснениях не нуждается — я добавил кое-где комментарии и докстринги, чтобы было понятнее. С представлением блокчейна мы практически закончили. Но сейчас вы, должно быть, задаетесь вопросом, как происходит процесс создания, встраивания и майнинга блоков.
Разбираемся с доказательством работы
Алгоритм доказательства работы служит для создания новых блоков в блокчейне (это процесс еще называется майнингом). Цель доказательства работы — вычислить нужное значение, чтобы решить уравнение. Это значение должно быть сложно рассчитать (с математической точки зрения), но легко проверить любому участнику системы. В этом заключается основная идея доказательства работы.
Чтобы стало яснее, давайте рассмотрим очень простой пример.
Допустим, хэш некоторого числа X, помноженного на другое Y, должен оканчиваться на 0. Соответственно, hash(x * y) = ac23dc...0. Для этого упрощенного примера установим x = 5. Прописываем все это на Python:
Правильный ответ здесь: y = 21; именно при таком значении получается хэш с 0 в конце:
В биткойне алгоритм доказательства работы называется HashCash и не особенно отличается от простенького примера, приведенного выше. Это уравнение, которые майнеры наперегонки пытаются разрешить, чтобы создать новый блок. В целом, сложность определяется тем, сколько символов нужно вычислить в заданной последовательности. За верный ответ майнеры получают вознаграждение в виде одной монеты — в ходе транзакции.
Проверить их решение для системы не составляет труда.
Пишем простое доказательство работы
Теперь давайте пропишем подобный же алгоритм для нашего блокчейна. Условия возьмем в духе вышеприведенного примера:
Найдите число p, которое, будучи хэшировано с доказательством предыдущего блока, дает хэш с четырьмя нулями в начале.
Мы можем варьировать сложность этой задачи, меняя количество нулей в начале. Но четырех вполне достаточно. Вы можете сами убедиться, что один-единственный дополнительный нолик значительно замедляет процесс поиска решения.
Работа над классом почти завершена и теперь мы готовы начать взаимодействие с ним при помощи HTTP запросов.
Шаг второй: Блокчейн как API
Здесь мы будем использовать Python Flask — микрофреймворк, который облегчает процесс соотнесения конечных пунктов с функциями Python, что позволяет нам осуществлять диалог с блокчейном по Сети при помощи HTTP запросов.
Создаем три метода:
- /transactions/new для создания новой транзакции в блоке
- /mine для майнинга нового блока на сервере
- /chain для возвращения полной цепочки блокчейна.
Настраиваем Flask
Наш «сервер» сгенерирует один-единственный узел сети в блокчейн-системе. Давайте напишем немного шаблонного кода:
Краткие пояснения к тому, что мы добавили:
Строка 15: Инстанцирует узел. Подробнее о Flask можно почитать здесь.
Строка 18: Создает произвольное имя для узла.
Строка 21: Инстанцирует класс Blockchain.
Строки 24-26: Создает конечную точку /mine, то есть запрос GET.
Строки 28-30: Создает конечную точку /transactions/new, то есть запрос POST, так как именно туда мы и будем отсылать данные.
Строки 32-38: Создает конечную точку /chain, который возвращает блокчейн целиком.
Строки 40-41: Запускает сервер на порту 5000.
Конечный пункт для транзакций
Вот как будет выглядеть запрос на транзакцию. Именно это пользователь отсылает на сервер:
Метод класса для добавления транзакции в блок у нас уже есть, поэтому дальше все легко. Давайте напишем функцию для добавления транзакции:
Конечный пункт для майнинга
Именно в этой конечной точке творится вся магия, но ничего особо сложного в нем нет. Она должна делать три вещи:
- Рассчитывать доказательство работы
- Выдавать майнеру (то есть нам) вознаграждение, добавляя транзакцию, с ходе которой мы получаем одну монету
- Встраивать новый блок в цепочку
Обратите внимание, что в качестве получателя созданного блока указан адрес узла. Большая часть того, что мы тут делаем, сводится к взаимодействию с методами нашего класса Blockchain. По завершению этого шага основная работа закончена, можно начинать диалог.
Шаг третий: Диалог с блокчйном
Для взаимодействия с API в рамках системы можно использовать старый-добрый cURL или Postman.
Запускаем сервер:
Давайте попробуем создать блок, отправив запрос GET по адресу localhost:5000/mine:
Теперь создаем новую транзакцию, отправив запрос POST, содержащий ее структуру, по адресуlocalhost:5000/transactions/new:
Если вы работаете не с Postman, вот как сформулировать аналогичный запрос в cURL:
Я перезапустил сервер и создал еще два блока, чтобы в итоге получилось три. Давайте изучим получившуюся цепочку через запрос localhost:5000/chain:
Шаг четвертый: Консенсус
Все это очень здорово. У нас есть простой блокчейн, который позволяет осуществлять транзакции и создавать новые блоки. Но блокчейн имеет смысл только в том случае, если он децентрализован. А если сделать его децентрализованным, как мы вообще можем гарантировать, что везде будет отображаться одна и та же цепочка? Это называется проблемой консенсуса. Если мы хотим, чтобы в системе было больше одного узла, придется ввести алгоритм консенсуса.
Распознаем новые узлы
Прежде чем внедрять алгоритм консенсуса, нам нужно что-то предпринять, чтобы каждый узел в системе знал о существовании соседних. У каждого узла в системе должен быть реестр всех остальных узлов. А значит понадобятся дополнительные конечные точки:
- /nodes/register, который будет принимать список новых узлов в URL формате
- /nodes/resolve для внедрения алгоритма консенсуса, который будет разрешать возникающие конфликты и отслеживать, чтобы в узле содержалась правильная цепочка.
Нам нужно подкорректировать конструктор блокчейна и обеспечить метод для регистрации узлов:
Заметьте: мы использовали set() для хранения списка узлов. Это нехитрый способ гарантировать, что при добавлении новых узлов будет соблюдаться индемпотентность — то есть сколько бы раз мы ни добавляли какой-то конкретный узел, он будет засчитан только единожды.
Внедряем алгоритм консенсуса
Как я уже упоминал, конфликт происходит тогда, когда цепочка одного узла отличается от цепочки другого. Чтобы его устранить, мы введем такое правило: прерогатива всегда у той цепочки, которая длиннее. Иными словами, самая длинная цепочка в системе рассматривается как фактическая. Используя такой алгоритм, мы достигаем консенсуса среди всех узлов системы:
Первый метод valid_chain() отвечает за проверку цепочек на валидность, проходя каждый блок и верифицируя и хэш, и доказательство.
resolve_conflicts() — метод, который прорабатывает все соседние узлы: скачивает их цепочки и проверяет их описанным выше способом. Если при этом найдена валидная цепочка длиннее, чем наша, производится замена.
Давайте введем в наш API две конечные точки, один для добавления соседних узлов, другой для разрешения конфликтов:
На данном этапе, если хотите, можете привлечь другие машины и насоздавать разных узлов для вашей системы. Или добиться того же используя разные порты на одной машине. Я создал новый узел на другом порте той же машины, и позволил исходному узлу его распознать. Таким образом, получилось два узла: localhost:5000 и localhost:5001.
В узел номер два я добавил побольше блоков, чтобы цепочка получилась однозначно длиннее. После чего вызвал GET /nodes/resolve в первом узле — и алгоритм консенсуса заменил его цепочку на цепочку второго.
Ну, вот и все. Теперь собирайте друзей и тестируйте вам блокчейн совместными усилиями.
Надеюсь, этот материал вдохновит вас на новые идеи. Лично я с большим энтузиазмом наблюдаю за развитием криптовалюты: я уверен, что блокчейн перевернет наши представления об экономике, управлении государством и хранении информации.
В будущем я планирую выпустить вторую часть статьи, где мы добавим в блокчейн механизм валидации транзакций и поговорим о том, как все это можно использовать в продуктах.
Источник: https://habrahabr.ru/company/everydaytools/blog/339280/
Комментариев нет:
Отправить комментарий